Requires GIT workflow suggestion
I've been researching GIT for the past couple of weeks trying to get my team's code under control. Unfortunately, the code we are working with is a proprietary language with some quirks that prevent me from finding a reasonably practical workflow to implement. However, I probably don't know all the features of GIT, so I'm asking you guys for a suggestion. I would split this message into three: 1) like my files; 2) the workflow, which we have guessed so far; 3) options that I look forward to.
My files then;
As I said, this is a proprietary script language in which inside the code itself you will find tags related to configurations (servers, databases, and others). This may sound strange, I know, but technically this code is a large, complex configuration file. Well it can't be changed, now let's just leave it.
I also have two different environments: dev
and prod
, and I assume this is obvious. Due to the odd way of parsing the code, if you compare a script in dev
with the same in prod
, you will see:
prod:
CodeCode += Code(0)
Code{1} ...
CodeConfig = "ConnectionToProducionDB"
SomeMoreGenericCode.doSomething()
(...)
And in dev it will look like this:
CodeCode += Code(0)
Code{1} ...
CodeConfig = "GoToSomeDevDB"
SomeMoreGenericCode.doSomething()
(...)
This applies to files.
Now what has been shown
At first glance, it seemed to me that the classic branch was putting pressure on this situation, and so I did.
[create a folder and init it]
[copy my code from production and add/commit it]
$ git checkout -b dev
[change these lines with 'CodeConfig' to the dev settings]
[go happy coding and commiting]
After a while, coding and tests are done and it's time to merge into production. This is when the problem starts.
A simple one git merge dev
(from my master branch) will merge the codes mostly in order, but the configs will also be pushed to the master branch as from the GIT POV this is one of the updates to the code itself. While this is not a problem in this shortcode, in a real-world situation I could reconfigure ten or twenty sources and roll back in time - not a very pleasant (and not reliable) task.
Of course, when using branches, I want to be able to combine my code to keep my commit history and comments. I just need this to be done more individually ...
I've tried a couple of different things to get around this but have no success. Seems like GIT merge is too smart for me :(
For example, *.xml merge=Unset
to my .gitattributes
file. Or the custom merge driver in ~ / .gitconfig is trying to cause auto-merge to fail (not sure if I got this right though).
Possible solutions I thought:
As I said, I probably don't know all the GIT features, so my options are related by those I know. I appreciate your innovation;)
I though the easiest way would be if I could turn off auto merge and do it all manually (the codes are not that big and I still have to look into it). After that, I'll create a simple merge driver that will push all code changes (not just conflicts) to something like WinMerge or Kdiff3, where I would do the job. Unfortunately, I have not been able to do this yet.
My last attempt resulted in a lengthy and impractical workflow, but I'll post it here so you can understand my purpose.
- init repo
proj1
- copy
prod
files - add / commit first
-
$ git checkout -b dev
- adjust
dev
parameters - code / commit dev cycle
- copy dev files to
tmpDevDir
-
$ git checkout master
- use WinMerge to compare
tmpDevDir
withproj1[master branch]
and apply only the changes you want. - commit
proj1[master branch]
-
$ git merge dev
- merge conflicts where necessary
-
$ git diff HEAD HEAD^
to view the result of the merge and return the merged configurations -
$ git commit -am 'final commit for the production code'
And good ... not nice.
Anyone have ideas for a more practical workflow or other commands to help with this?
Many thanks,
e.
source to share
This is the classic "config file" situation (even if your files are not exactly a config file).
- put only variable names in your code
- extract values specific to each environment in their files
- version of a script is capable of generating actual code (one in which variable names have been replaced with their values depending on the current environment)
- set a filter (see Git ProBook ) to automate variable substitution (which means no "new files" are created: only the current code changes to
git checkout
- variable replaced by values - and "cleared" togit commit
- values are replaced by variables and values are returned to separate configuration file if changed)
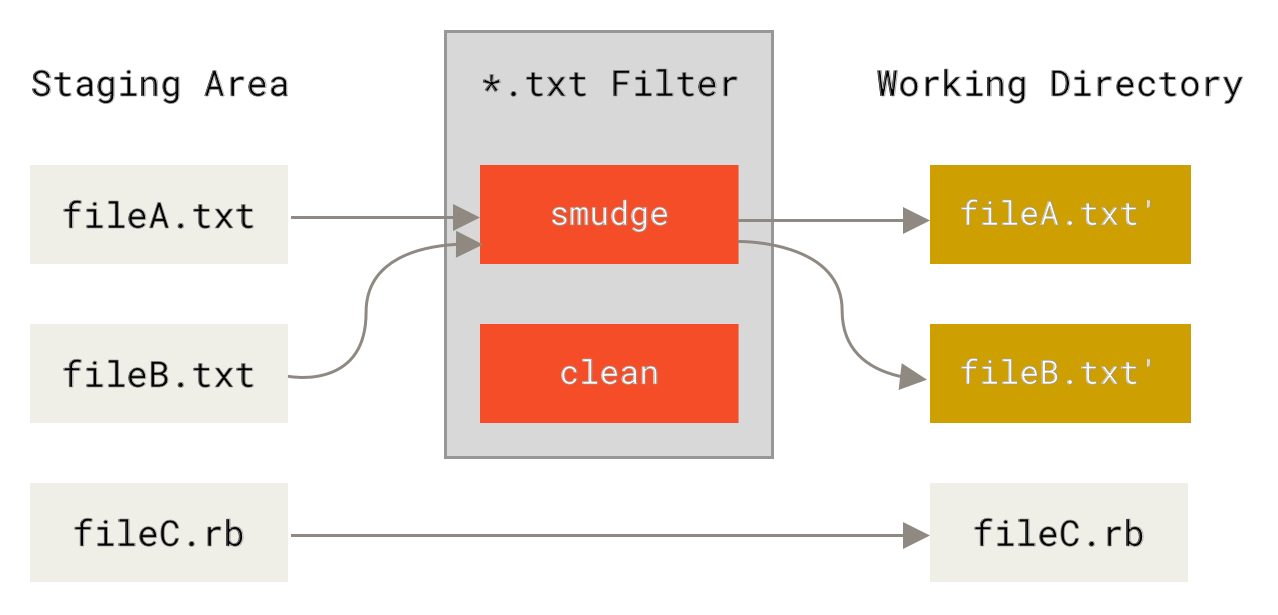
This way, you don't have to create separate branches just because you have separate values in some files.
No complicated merging, copying between branches, etc.
Just:
yourCode1.code
yourCode2.code
...
yourCoden.code
devValues.txt
prodValues.txt
scriptPutValuesInCode.sh
scriptCleanCodeFromValues.sh
*.code filter=setOrCleanValues
git config --global filter.setOrCleanValues.smudge /path/to/scriptPutValuesInCode.sh
git config --global filter.setOrCleanValues.clean /path/to/scriptCleanCodeFromValues.sh
source to share