Python 3.4 filtering text file into lists
I am having trouble filtering a .txt file into sublists, which I can then turn into a directory. Sample from text.txt A2.-B4-...C4-.-.D3-..E1.F4..-.G3--.H4....75--...85---..95----.05-----.6.-.-.-,6--..--?6..--..!5..--.
with no spaces or lines, it is basically a line of text.
A2.- means that the character "A" has 2 characters in the morse -code, and they are .- etc.
What I would like to do is split this long string into sublists so that I can then zip it into a directory, which I can then use to create a morse-code translator. What I would like to do: make a keyList containing the keys A, B, C, ...,?,.,
And another list of valuesList, which contains the values for the keys.
However, since the keys are not letters that have problems filtering all over the file.
What I have tried:
import re
r = open("text.txt", "r")
ss = r.read()
p = re.compile('\w'+'\w')
keyList = p.findall(ss)
ValueList = p.split(ss)
print(keyList)
print(ValueList)
keyList = ['A2', 'B4', 'C4', 'D3',..., '75', '85', '95', '05']
ValueList = ['', '.-', '-...', '-.-.', '-..', space , !5..--.']
As you can see, the valueist will not split properly because '\ w' + '\ w' will only match alpha numeric characters. I tried changing the argument to re.compile but couldn't find anything that worked. Any help? is re.compiled the best way to do this or is there another way to filter through text?
EDIT: expected / desired output:
keyList = ['A','B','C','D',...,'.','?',',']
ValueList = ['.-','-...','-.-.','-..',...,'.-.-.-','..--..','--..--']
source to share
To create an encoder / decoder, you probably want to use dictionaries, not lists.
When it comes to parsing, a straight forward naive approach is probably best suited here.
result = {}
with open('morse.txt', 'r') as f:
while True:
key = f.read(1)
length_str = f.read(1)
if len(key) != 1 or len(length_str) != 1:
break
try:
length = int(length_str)
except ValueError:
break
value = f.read(length)
if len(value) == length:
result[key] = value
for k, v in result.items():
print k, v
leads to:
A .-
! ..--.
C -.-.
B -...
E .
D -..
G --.
F ..-.
H ....
, --..--
. .-.-.-
0 -----
7 --...
9 ----.
8 ---..
? ..--..
source to share
You can try this:
items = re.findall(r'(.\d)([\.-]+)', ss)
keys = [s[0][0] for s in items]
values = [s[1] for s in items]
I got:
>>> keys
['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', '7', '8', '9', '0', ',', '?', '!']
values
['.-', '-...', '-.-.', '-..', '.', '..-.', '--.', '....', '--...', '---..', '----.', '-----.', '--..--', '..--..', '..--.']
source to share
Like Cuadue's answer , I would use a loop to parse it, but I would do it in reverse:
morse_str = 'A2.-B4-...C4-.-.D3-..E1.F4..-.G3--.H4....75--...85---..95----.05-----.6.-.-.-,6--..--?6..--..!5..--.'
morse_list = list(morse_str)
morse_dict = {}
while morse_list:
morse = ''
while True:
sym = morse_list.pop()
try:
int(sym)
except ValueError:
morse += sym
else:
key = morse_list.pop()
morse_dict[key] = morse[::-1]
break
source to share
You can use positive prediction in regular expressions to find keys :
>>> s = 'A2.-B4-...C4-.-.D3-..E1.F4..-.G3--.H4....75--...85---..95----.05-----.6.-.-.-,6--..--?6..--..!5..--.'
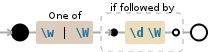
>>> keys = re.findall(r'[\w|\W](?=\d\W)',s)
['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', '7', '8', '9', '0', '.', ',', '?', '!']
Since you have no alphabetic characters, such as !
and ,.
in your keys and values, you can not use jut one re
to obtain the expected values, you can use this template split()
to split the string based on your keys so that you get the expected value with one digit in beginning and then remove that digit with re.sub()
:
>>> values = [re.sub('\d','',i) for i in re.split(r'[\w|\W](?=\d)',s) if len(i)]
['.-', '-...', '-.-.', '-..', '.', '..-.', '--.', '...', '--..', '---.', '----', '-----', '.-.-.-', '--..--', '..--..', '..--.']
so it is important that you have the same len
for keys
and values
:
>>> len(keys)
16
>>> len(values)
16
and finally zip them:
>>> dict(zip(keys,values))
{'A': '.-', '!': '..--.', 'C': '-.-.', 'B': '-...', 'E': '.', 'D': '-..', 'G': '--.', 'F': '..-.', 'H': '...', ',': '--..--', '.': '.-.-.-', '0': '-----', '7': '--..', '9': '----', '8': '---.', '?': '..--..'}
source to share