Select everything but a specific regex from a list in R
I want to replace everything from a list that does NOT match the given pattern. I am using R version 3.1.3 (2015-03-09) - "Smooth Sidewalk"
The list of examples I have:
y <- c("D CCNA_01234 This is example 1 bis", "D CCNA_02345 This is example 2", "D CCNA_12345 This is example 3", "D CCNA_23468 This is example 4")
and the pattern I want to match is CCNA_01234, where the numbers don't match in every case, but always have 5 digits.
Desired result:
"CCNA_01234" "CCNA_02345" "CCNA_12345" "CCNA_23468"
so far i have removed the previous part to match:
y_begin_rm <- sub("D ", "", y)
but I have problems recognizing the match with the expression [^ match].
y_CCNA_numbers <- sub("[^CCNA_[0-9][0-9][0-9][0-9][0-9]]*$", "", y_begin_rm)
which outputs the result:
[1] "CCNA_01234 This is example 1 bis" "CCNA_02345 This is example 2"
[3] "CCNA_12345 This is example 3" "CCNA_23468 This is example 4"
The problem seems to be that the numbers given in the match appear all the way through the string and not in the exact combination I want. So the number after the phrase "this is an example" causes a lot of problems. When I omit the numbers, or place a digit that is only after the CCNA_string, it works just fine:
y_CCNA <- sub("[^CCNA_]*$", "", y_begin_rm)
performs
[1] "CCNA_" "CCNA_" "CCNA_" "CCNA_"
or
y_CCNA_0 <- sub("[^CCNA_0]*$", "", y_begin_rm[1])
leads to
[1] "CCNA_0"
Is there a way to specify the exact pattern I'm looking for (CCNA_ [0-9] [0-9] [0-9] [0-9] [0-9])? Also, is there a possible way to do this in one step (remove before and after match in one regex)?
Thanks in advance!
source to share
Here are some ways:
1) strapplyc . It uses a particularly simple pattern. It uses strapplyc
in the gsubfn package:
library(gsubfn)
strapplyc(y, "CCNA_\\d{5}", simplify = TRUE)
## [1] "CCNA_01234" "CCNA_02345" "CCNA_12345" "CCNA_23468"
Here's a visualization of the regex:
CCNA_\d{5}
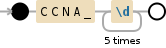
1a) If the only occurrences of CCNA_ are up to 5 digits, we can simplify the previous solution a little as follows:
strapplyc(y, "CCNA_.{5}", simplify = TRUE)
## [1] "CCNA_01234" "CCNA_02345" "CCNA_12345" "CCNA_23468"
2) sub . The template is a little more complicated here, but with the help sub
we can do it without any package addons:
sub(".*(CCNA_\\d{5}).*", "\\1", y)
## [1] "CCNA_01234" "CCNA_02345" "CCNA_12345" "CCNA_23468"
3) strsplit If the desired part is always the second "word" (which is the case in the question) then this will work and again does not require packages:
sapply(strsplit(y, " "), "[", 2)
## [1] "CCNA_01234" "CCNA_02345" "CCNA_12345" "CCNA_23468"
4) substr If the desired part always contains characters 3 through 12, as in the question, then we could use substr
or substring
, again, without any packages:
substr(y, 3, 12)
## [1] "CCNA_01234" "CCNA_02345" "CCNA_12345" "CCNA_23468"
source to share
With base R, you can just do straight from your original vector y
sub(".*(CCNA_\\d+).*", "\\1", y)
## [1] "CCNA_01234" "CCNA_02345" "CCNA_12345" "CCNA_23468"
Another option is to use stringi
library(stringi)
stri_extract_first_regex(y, "CCNA_\\d+")
## [1] "CCNA_01234" "CCNA_02345" "CCNA_12345" "CCNA_23468"
If you have more than one pattern CCNA
on each line, use stri_extract_all_regex
instead
If you want to exactly match the 5 digits after CCNA_
you can also do
stri_extract_first_regex(y, "CCNA_\\d{5}")
## [1] "CCNA_01234" "CCNA_02345" "CCNA_12345" "CCNA_23468"
And of course similarly stringr
library(stringr)
str_extract(y, "CCNA_\\d{5}")
## [1] "CCNA_01234" "CCNA_02345" "CCNA_12345" "CCNA_23468"
source to share
Here's a package-using approach, I support qdapRegex (I prefer this or stringi / stringr) for consistency and ease of use. I am also showing the basic approach. In any case, I would look at this more as a "fetch" problem than a "sub all but" subbing problem.
y <- c("D CCNA_01234 This is example 1 bis", "D CCNA_02345 This is example 2",
"D CCNA_12345 This is example 3", "D CCNA_23468 This is example 4")
library(qdapRegex)
unlist(rm_default(y, pattern = "CCNA_\\d{5}", extract = TRUE))
## [1] "CCNA_01234" "CCNA_02345" "CCNA_12345" "CCNA_23468"
In the R base:
unlist(regmatches(y, gregexpr("CCNA_\\d{5}", y)))
## [1] "CCNA_01234" "CCNA_02345" "CCNA_12345" "CCNA_23468"
source to share