Numpy arange values change unexpectedly
I talk a little bit about numpy
and I used some of my old texts to use as examples. So, I wrote a function without numpy
to calculate the deflection in the cantilever beam due to one point load at any point. Pretty straight forward, except that the deflection equation changes depending on which side of the point force you are on, so I split the beam into two ranges, calculated the deflection values at each interval in the ranges, and added the result to the list. Here is the code.
def deflection(l, P, a, E, I):
"""
Calculate the deflection of a cantilever beam due to a simple point load.
Calculates the deflection at equal one inch intervals along the beam and
returns the deflection as a list along with the the length range.
Parameters
----------
l : float
beam length (in)
P : float
Point Force (lbs)
a : float
distance from fixed end to force (in)
E : float
modulus of elasticity (psi)
I : float
moment of inertia (in**4)
Returns
-------
list
x : distance along beam (in)
list of floats
y : deflection of beam (in)
Raises
------
ValueError
If a < 0 or a > l (denoting force location is off the beam)
"""
if (a < 0) or (a > l):
raise ValueError('force location is off beam')
x1 = range(0, a)
x2 = range(a, l + 1)
deflects = []
for x in x1:
y = (3 * a - x) * (P * x**2) / (6 * E * I)
deflects.append(y)
for x in x2:
y = (3 * x - a) * (P * a**2) / (6 * E * I)
deflects.append(y)
return list(x1) + list(x2), deflects
Now I want to do the same with numpy, so I wrote the following function:
def np_deflection(l, P, a, E, I):
"""To Do. Write me."""
if (a < 0) or (a > l):
raise ValueError('force location is off beam')
x1 = np.arange(0, a)
x2 = np.arange(a, l + 1)
y1 = (3 * a - x1) * (P * x1**2) / (6 * E * I)
y2 = (3 * x2 - a) * (P * a**2) / (6 * E * I)
return np.hstack([x1, x2]), np.hstack([y1, y2])
Here is the problem, at some point in the calculations, the value of y1 changes sign. Here's an example.
if __name__ == '__main__':
import matplotlib.pyplot as plt
l, P, a, E, I = 120, 1200, 100, 30000000, 926
x, y = deflection(l, P, a, E, I)
print(max(y))
np_x, np_y = np_deflection(l, P, a, E, I)
print(max(np_y))
plt.subplot(2, 1, 1)
plt.plot(x, y, 'b.-')
plt.xlabel('dist from fixed end (in)')
plt.ylabel('using a range/list')
plt.subplot(2, 1, 2)
plt.plot(np_x, np_y, 'r.-')
plt.xlabel('dist from fixed end (in)')
plt.ylabel('using numpy range')
plt.show()
If you run the graph, you will see that there is a dislocation on the curve at the point x = 93
that is at x1
, where the value seems to change sign. 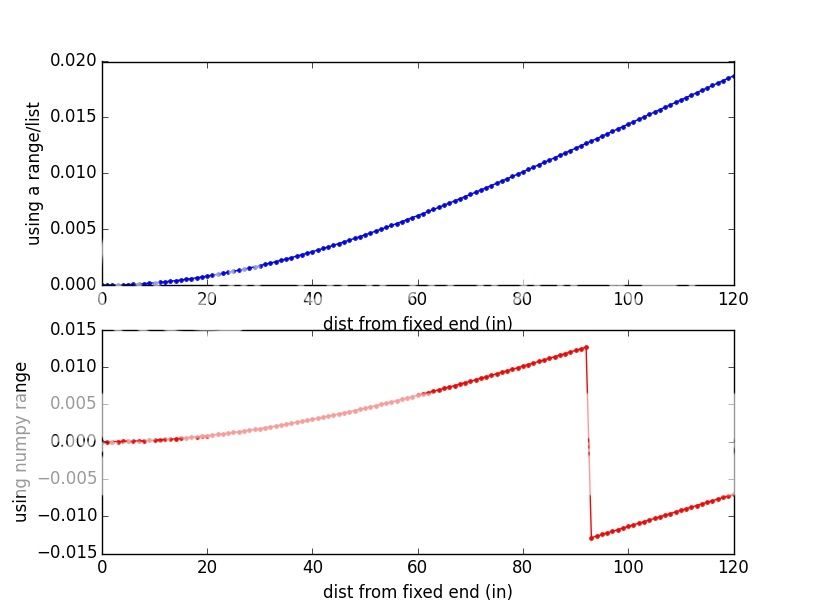 Can anyone explain a) what's going on? and b) what did I do wrong?
Can anyone explain a) what's going on? and b) what did I do wrong?
source to share
I'm pretty sure this has nothing to do with overflow as some people have suggested and anything related to the default dtype
for np.arange
. If you pass an integer start, stop and jump to arange
, then the output will be an integer array.
In python 2.x, the operator /
uses integer division.
For example:
import numpy as np
print np.arange(10) / 3
Results in:
[0 0 0 1 1 1 2 2 2 3]
However
np.arange(10, dtype=float) / 3
or
np.arange(10.0) / 3
or
np.arange(10) / 3.0
Will the result
[ 0. 0.33333333 0.66666667 1. 1.33333333 1.66666667
2. 2.33333333 2.66666667 3. ]
If you prefer that the operator /
always promotes results to floating point, you can use from __future__ import division
.
An alternative option is to know the data type of your arrays. Numpy allows you to have a very low level of control over how data is stored in memory. This is very, very useful in practice, but it may seem a little surprising at first. Nevertheless, the rules for increasing the rating are quite simple and deserve attention. Basically, whenever two types are used in an operation, if they are the same, the type is preserved. Otherwise, the more general one is used.
source to share